在web开发中,要将更新的数据实时反映到UI上,就不可避免地要对DOM进行操作,而复杂频繁的DOM操作通常是产生性能瓶颈的原因之一。React引入了Virtual DOM这个概念,Virtual DOM其实是JavaScript对象,对原生DOM进行操作的仅仅是diff部
分,因而大大地提升了性能。
接下来我就从以下几个方面对虚拟DOM进行讲解:Virtual DOM模型、 自定义组件的生命周期、setState机制、diff算法
Virtual DOM模型
Virtual DOM本质上是在浏览器端用JavaScript实现的一套DOM API。其中Virtual DOM模型负责Virtual DOM底层框架的构建工作,拥有一整套的Virtual DOM标签,并负责虚拟节点及其属性的构建、更新、删除等工作。Virtual DOM中的节点称为ReactNode,它分为三种类型:ReactFragment,ReactText,ReactELement。ReactFragment由一组ReactNode或者ReactEmpty构成,ReactText由string和number类型构成。而ReactElement又分为ReactDOMElement和ReactComponentElement。他们是对象类型,包括type,props,key,ref这些基本属性。其中ReactDOMElement的type是string,例如’div’, 而ReactComponentELement的type是一个表示组件的函数或者是类。
通过JSX语法创建虚拟元素时,实际上会调用React.createElement()方法,这个方法会对props进行合并,处理children,全部挂在到props的children属性上,然后返回一个ReactElement实例。
创建组件时,首先会调用instantiateReactComponent,它通过判断node的类型来决定创建哪一类组件。当node为空时,会创建一个ReactDOMEmptyComponent,当node的类型为string或number时,其实是不算Virtual DOM的,但是React为了保持渲染的一致性,将其封装为文本组件,会创建一个ReactDOMTextComponent。当node的类型为对象时,判断type的值,如果为string,会创建一个DOM标签组件ReactDOMComponent。否则创建一个自定义组件ReactCompositeComponent。
自定义组件的生命周期
组件的生命周期在不同的状态下会有不同的执行顺序:
- 当首次装载组件时,按顺序执行 getDefaultProps、getInitialState、componentWillMount、render 和 componentDidMount;
- 当卸载组件时,执行 componentWillUnmount;
- 当重新装载组件时,此时按顺序执行 getInitialState、componentWillMount、render 和 componentDidMount,但并不执行 getDefaultProps;
- 当再次渲染组件时,组件接收到更新状态,此时按顺序执行 componentWillReceiveProps、shouldComponentUpdate、componentWillUpdate、render 和 componentDidUpdate。
(详细内容待补充)
setState机制
React是通过管理状态来实现对组件的管理的,state是组件的内部状态,在构造函数中通过对this.state赋值进行state的初始化,通过this.state访问state,通过this.setState设置state,当调用this.setState时React会重新调用render方法重新渲染UI。在我没有看setState源码之前,会有这样的疑问:
- setState是同步更新还是异步更新
- 调用setState一定能触发重新渲染吗
- 什么时候不可以用setState
(这里我想先问一下各位,知道这些问题的答案吗?)
所以,接下来我们看一下setState的源码,看看setState机制的内部原理是怎么样的,然后再来解决这几个问题。
这是setState的入口。接受两个参数,partialState和callback。从名字上就可以看出来setState做的是修改一部分state,而不是完全替换原来的state。也可以传一个callback函数,其实看到这个callback,我们应该就会觉得setState是异步更新的,但是其实没有这么简单。接着看源码。src/isomorphic/modern/class/ReactBaseClasses.js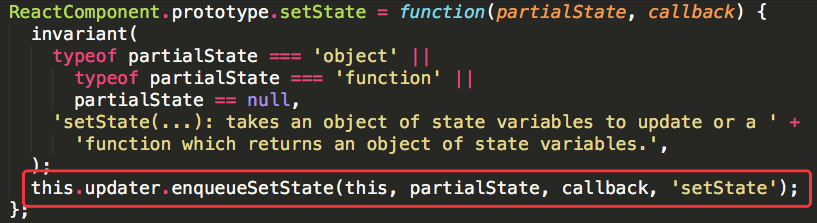
入口里调用了enqueueSetState函数,这个函数长这样:src/renderers/shared/stack/reconciler/ReactUpdateQueue.js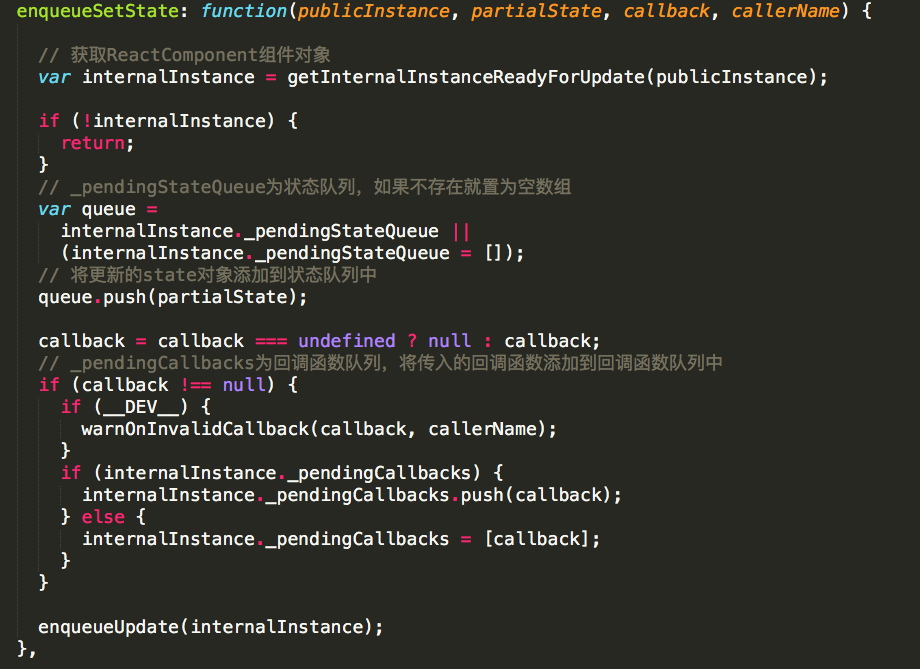
首先会获取当前组件的实例,这里说一下,构造函数执行时还没有保存当前组件的实例,所以如果是在构造函数中调用setState,这里会返回undefined,然后直接return,不再继续往下执行。因此在constructor中调用setState是没有用的。接着,会获取组件实例的_pendingStateQueue状态队列,如果不存在就置为空数组。将此次更新的partialState添加到状态队列中。然后也将callback函数添加到_pendingCallbacks队列中。最后调用exqueueUpdate函数。src/renderers/shared/stack/reconciler/ReactUpdate.js
这个函数里首先会判断batchingStrategy.isBatchingUpdates这个变量的值,这个变量是一个全局变量,表示是否处于批处理中,如果不是正处于创建或更新组件阶段,则执行batchingStrategy.batchedUpdates这个函数去进行更新,如果批处理正在进行中,则将组件实例添加到dirtyComponents队列中。接着将组件实例的_updateBatchNumber属性设置为当前批处理计数值加一。(设置这个属性的原因还没完全搞明白)
看到这里我们就可以知道,setState能不能立刻得到更新其实是由batchingStrategy.isBatchingUpdates来决定的。
接着看一下处理update的过程src/renderers/shared/stack/reconciler/ReactDefaultBatchingStrategy.js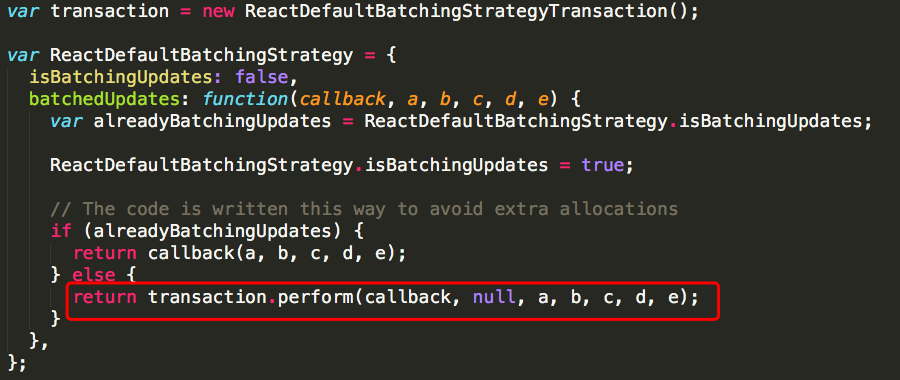
batchedUpdates内首先会保存一下当前的isBatchingUpdates属性的值,然后把它设置为true,接着判断之前的值,如果是true就直接执行传进来的callback函数,如果之前为false,则开启一个新的transaction。那么transaction事务是什么呢?src/renderers/shared/stack/reconciler/Transaction.js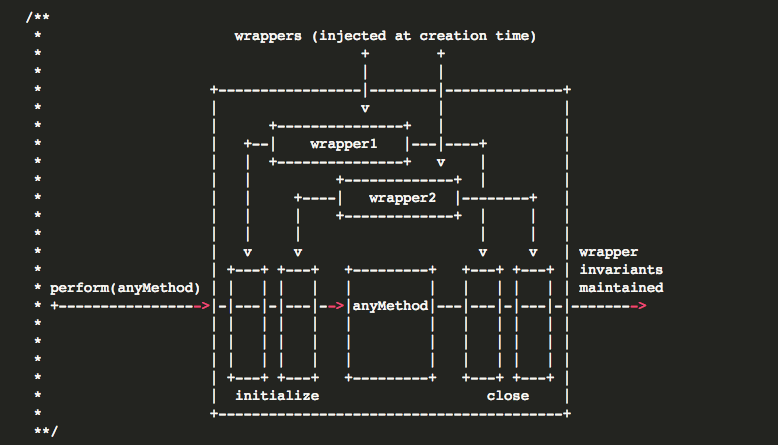
源码中有一幅图,形象地解释了事务的作用。事务就是将需要执行的方法使用wrapper封装起来,再通过事务提供的perform方法执行。而在perform之前,先执行所有wrapper中的initialize方法,执行完perform之后再执行所有的close方法。一组initialize及close方法称为一个wrapper,可以从图中看出,wrapper可以叠加。我们使用事务的过程是这样的:src/renderers/shared/stack/reconciler/ReactDefaultBatchingStrategy.js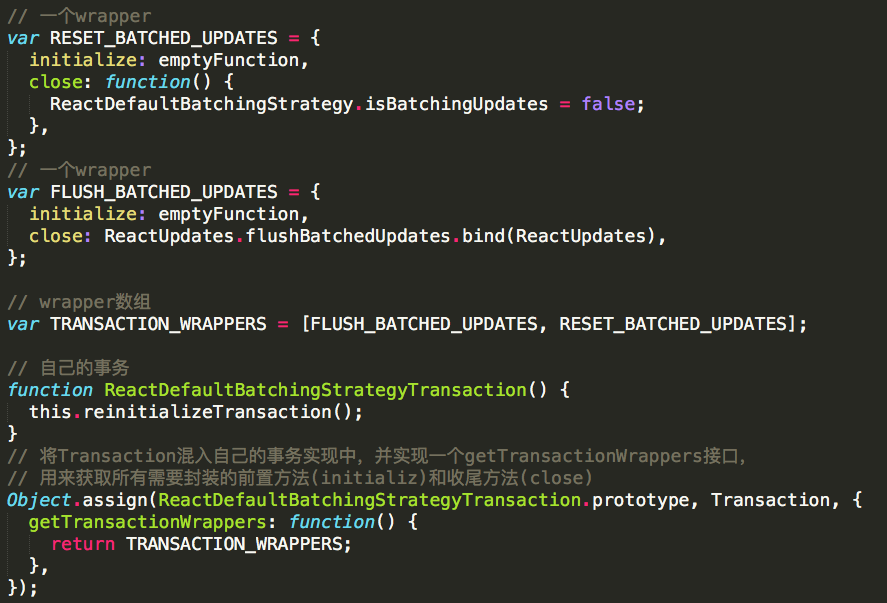
将Transaction混入自己的事务实现中,并实现一个getTransactionWrappers接口,用来获取所有需要封装的前置方法(initializ)和收尾方法(close)。
这里我们可以看到这个事务中有两个wrapper,FLUSH_BATCHED_UPDATES的close方法中执行了flushBatchedUpdates函数,这个函数内又执行了runBatchedUpdates函数,RESET_BATCHED_UPDATES的close方法中把batchingStrategy.isBatchingUpdates重新置为false。然后我们看一下具体的更新是怎么做的:src/renderers/shared/stack/reconciler/ReactUpdate.js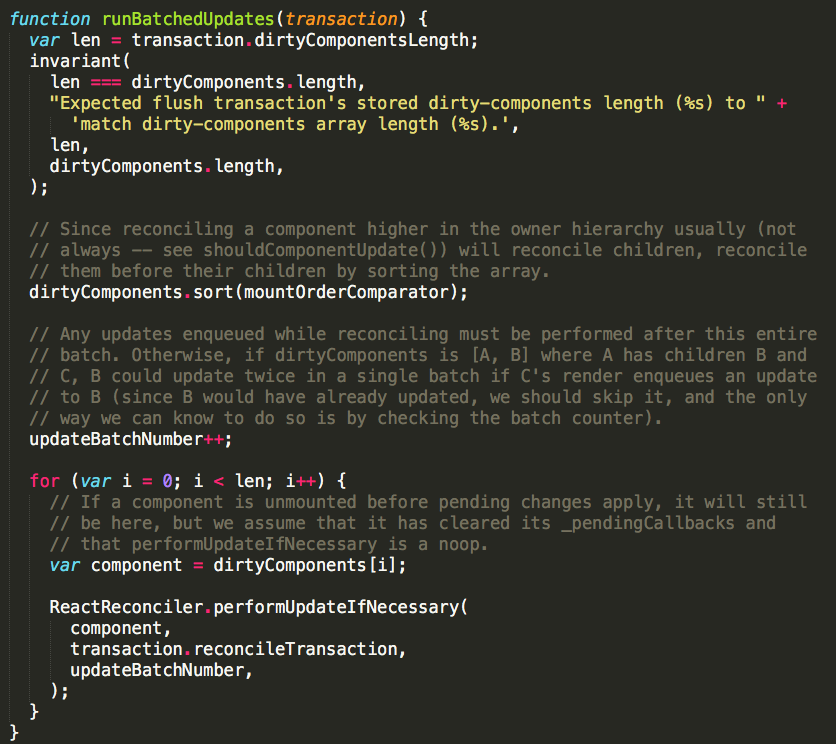
先是将dirtyComponents队列里的组件按照mount的顺序排序,因为调和的组件还有子组件的话,通常也需要调和子组件,应该先调和父组件再调和子组件。然后将updateBatchNumber加一(注释里描述的情况真是没看懂),然后遍历dirtyComponents队列,针对每一个组件执行performUpdateIfNecessary方法。src/renderers/shared/stack/reconciler/ReactReconciler.js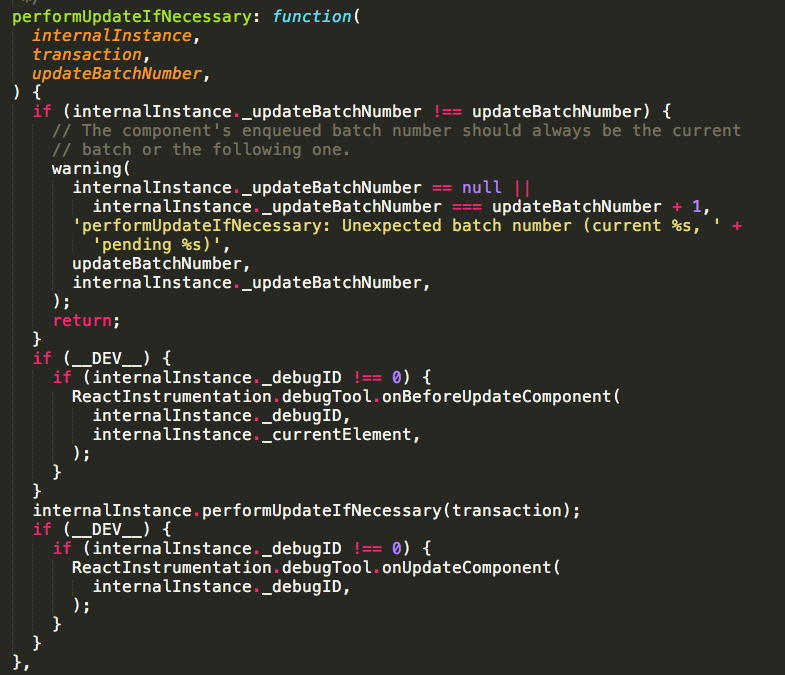
这个方法会比较组件的_updateBatchNumber属性和updateBatchNumber变量的值,_updateBatchNumber应该始终等于updateBatchNumber或者updateBatchNumber加一。(不理解)
如果成立则去执行组件实例的performUpdateIfNecessary方法src/renderers/shared/stack/reconciler/ReactCompositeComponent.js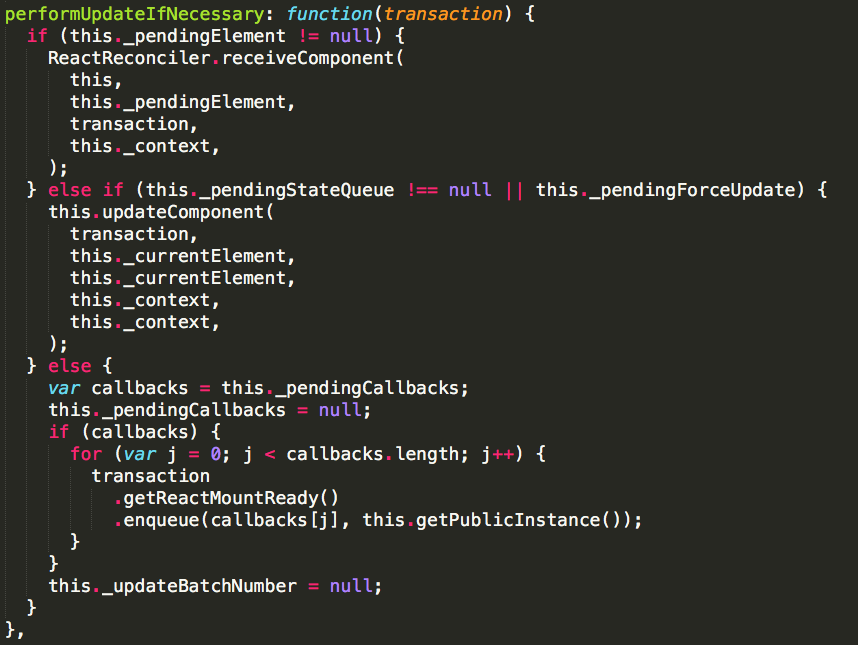
这个方法会去判断组件实例的_pendingStateQueue是否为空,如果不空的话就去执行updateComponent方法。src/renderers/shared/stack/reconciler/ReactCompositeComponent.js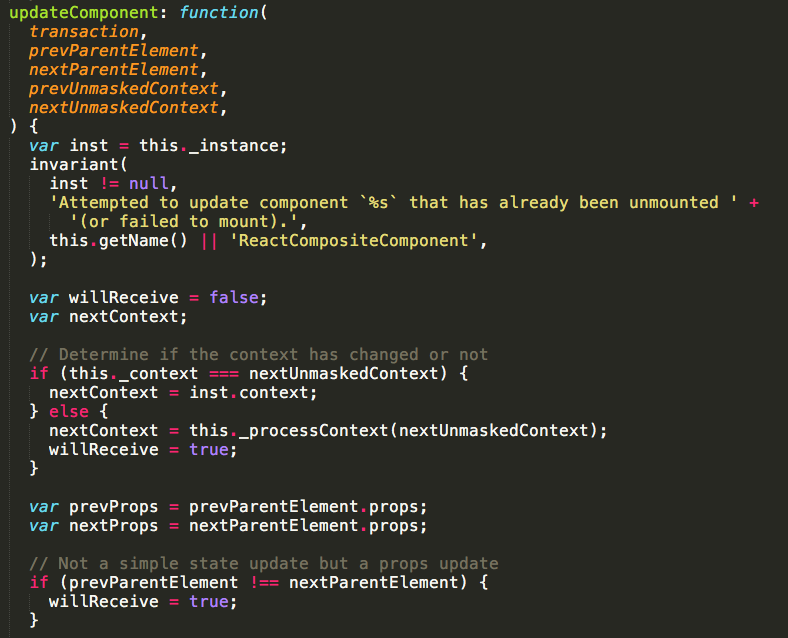
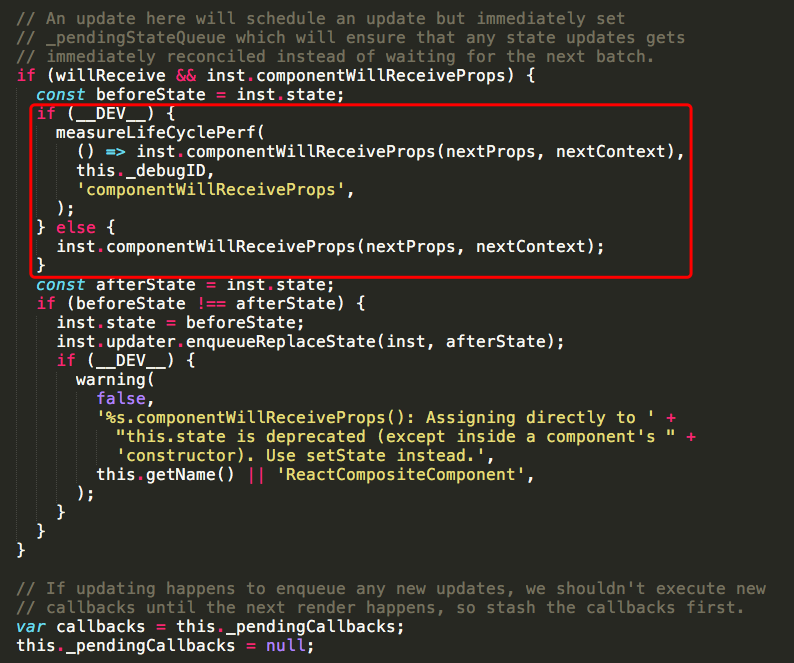
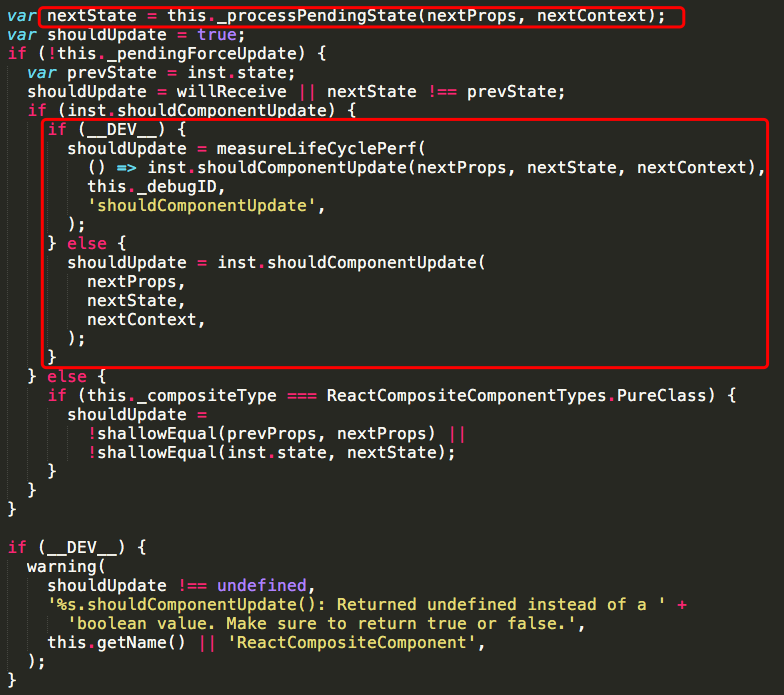
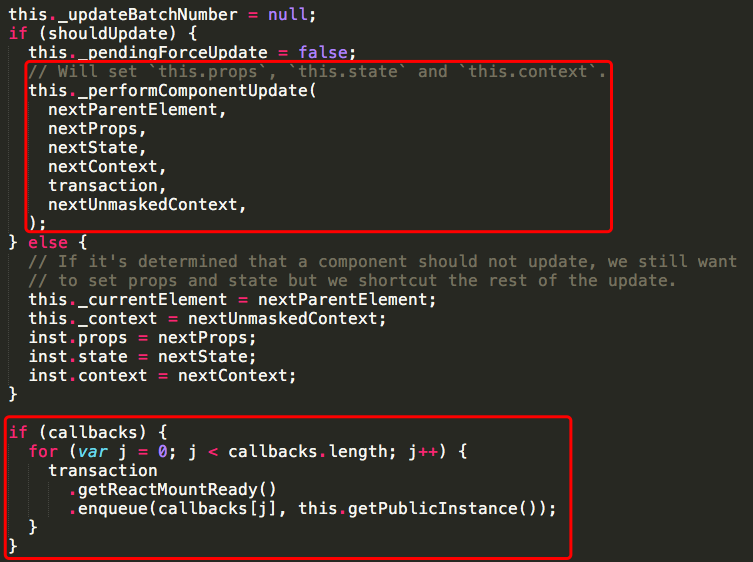
这个方法比较长,它主要做的工作是执行组件的update相关的生命周期,先执行componentWillReceiveProps,之后会去处理state的合并,然后执行shouldComponentUpdate,如果shouldComponentUpdate函数返回true,还会接着执行_performComponentUpdate函数,这个函数里会执行componentWillUpdate和componentDidUpdate生命周期函数。执行完这些函数后会执行所有的callback函数。至此,一次更新结束了。下面是简化的流程图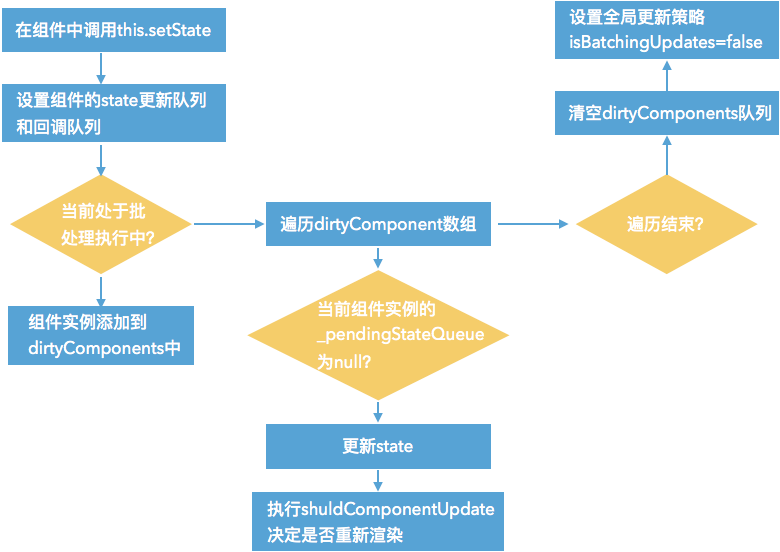
看完了setState的源码,现在让我们来回答前面提出的三个问题:
setState是同步更新还是异步更新?
setState是否能立刻更新是由batchingStrategy.isBatchingUpdates这个变量决定的。如下面的例子:
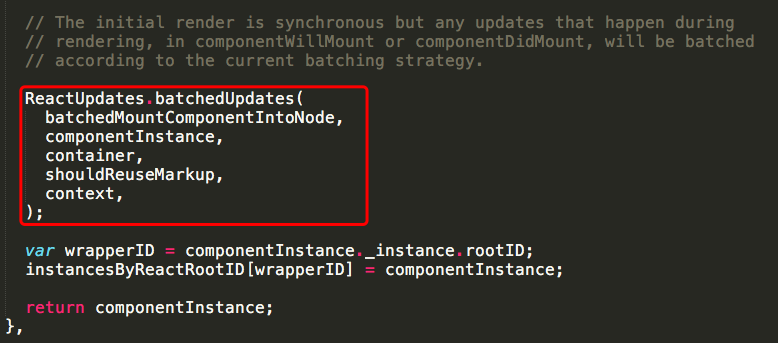
其实当将一个虚拟DOM渲染到真实的DOM节点上时,会执行ReactMount的_renderNewRootComponent函数,而这个函数中调用了batchedUpdate方法,将batchingStrategy.isBatchingUpdates置为true,因此前两次调用的setState会被放进状态队列中而不能立刻更新,而后两次的setState调用由于setTimeout函数的异步原因并没有立刻执行,所以前两次打印的结果应该是还没有改变的val,即0,而且两次setState都是在0的基础上加1,所以虽然执行了两遍,但是更新后的state只加了一次一,更新结果为1。而当此次批处理处理完之后事务的close函数会将batchingStrategy.isBatchingUpdates变量置为false,因此当setTimeout函数中的setState执行的时候batchingStrategy.isBatchingUpdates已经为false,因此可以立刻更新state,所以后两次打印的结果为2和3.
src/renderers/dom/stack/client/ReactMount.js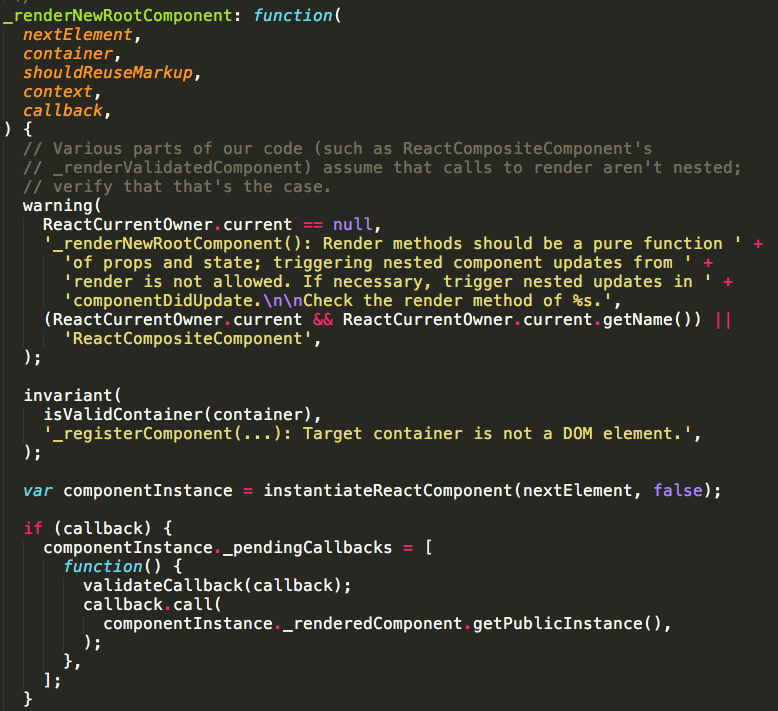
调用setState一定能触发重新渲染吗
先看一下componentWillMount相关的源码src/renderers/shared/stack/reconciler/ReactCompositeComponent.js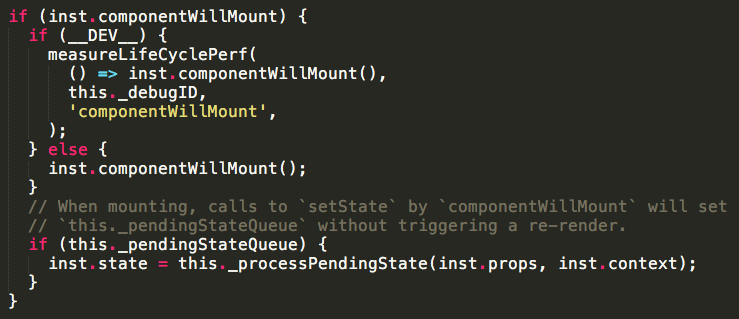
从源码中知道,会先执行componentWillMount,然后直接合并state,因此不会触发重新渲染
同理,从源码中也可以看到componentWillReceiveProps也是进行state合并,不会触发重新渲染。
componentWillUnmount中也不会触发重新渲染,因为会将所有更新队列重置为null。什么时候不可以用setState
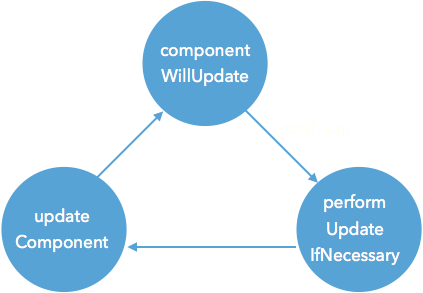
前面从源码中我们知道当调用setState之后实际会去调用performUpdateIfNecessary,而performUpdateIfNecessary中回去调用updateComponent,而updateComponent中又会去调用shouldComponentUpdate、componentWillUpdate和componentDidUpdate,所以如果在这三个函数中调用setState会造成循环调用,会导致浏览器内存占满后崩溃,所以不能在这几个函数中调用。(书上没有说componentDidUpdate,但是源码里updateComponent中确实执行了componentDidUpdate,我也实验了,这个函数确实会造成循环调用,所以我加上了componentDidUpdate)如果是在constructor中调用setState,获取组件对象实例时是获取不到的,因为该实例还没有存到ReactInstanceMap中,控制台会报一个warning。

如果在render中调用setState,react认为render应该是一个对props和state来说的纯函数,不应该在render中设置state。
diff算法
React diff 会帮助我们计算出前后两次 Virtual DOM 中真正变化的部分,并只针对该部分进行实际 DOM 操作,而非重新渲染整个页面,从而保证了每次操作更新后页面的高效渲染。传统 diff 算法的复杂度为 O(n^3),显然这是无法满足性能要求的。React 通过制定大胆的策略,将 O(n3) 复杂度的问题转换成 O(n) 复杂度的问题。
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
基于以上策略,React分别对 tree diff、component diff 以及 element diff 进行算法优化,事实也证明这三个前提策略是合理且准确的,它保证了整体界面构建的性能。
tree diff
对树进行分层比较,两棵树只会对同一层次的节点进行比较。维护一个updateDepth变量进行层级控制,当节点不存在,直接删除该节点及其子节点。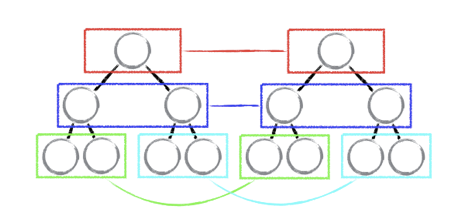
如下图,A 节点(包括其子节点)整个被移动到 D 节点下,当根节点发现子节点中 A 消失了,就会直接销毁 A;当 D 发现多了一个子节点 A,则会创建新的 A(包括子节点)作为其子节点。此时,React diff 的执行情况:create A -> create B -> create C -> delete A。其实这是一种影响 React 性能的操作,因此 React 官方建议不要进行 DOM 节点跨层级的操作。在开发组件时,保持稳定的 DOM 结构会有助于性能的提升。例如,可以通过 CSS 隐藏或显示节点,而不是真的移除或添加 DOM 节点。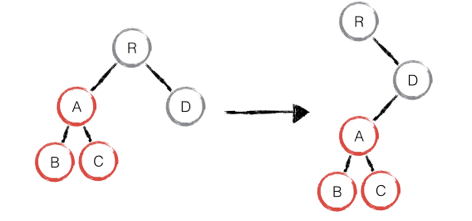
component diff
如果是同一类型的组件,按照原策略继续比较 virtual DOM tree。
如果不是,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切的知道这点那可以节省大量的 diff 运算时间,因此 React 允许用户通过 shouldComponentUpdate() 来判断该组件是否需要进行 diff。
如下图,当 component D 改变为 component G 时,即使这两个 component 结构相似,一旦 React 判断 D 和 G 是不同类型的组件,就不会比较二者的结构,而是直接删除 component D,重新创建 component G 以及其子节点。虽然当两个 component 是不同类型但结构相似时,React diff 会影响性能,但正如 React 官方博客所言:不同类型的 component 是很少存在相似 DOM tree 的机会,因此这种极端因素很难在实现开发过程中造成重大影响的。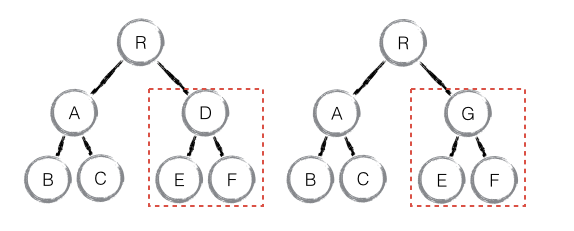
element diff
当节点处于同一层级时,React diff 提供了三种节点操作,分别为:INSERT_MARKUP(插入)、MOVE_EXISTING(移动)和 REMOVE_NODE(删除)。
- INSERT_MARKUP,新的 component 类型不在老集合里, 即是全新的节点,需要对新节点执行插入操作。
- MOVE_EXISTING,在老集合有新 component 类型,且 element 是可更新的类型,generateComponentChildren 已调用 receiveComponent,这种情况下 prevChild=nextChild,就需要做移动操作,可以复用以前的 DOM 节点。
- REMOVE_NODE,老 component 类型,在新集合里也有,但对应的 element 不同则不能直接复用和更新,需要执行删除操作,或者老 component 不在新集合里的,也需要执行删除操作。
如下图,老集合中包含节点:A、B、C、D,更新后的新集合中包含节点:B、A、D、C,此时新老集合进行 diff 差异化对比,发现 B != A,则创建并插入 B 至新集合,删除老集合 A;以此类推,创建并插入 A、D 和 C,删除 B、C 和 D。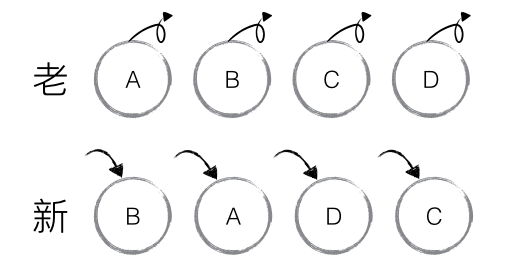
React 发现这类操作繁琐冗余,因为这些都是相同的节点,但由于位置发生变化,导致需要进行繁杂低效的删除、创建操作,其实只要对这些节点进行位置移动即可。
针对这一现象,React 提出优化策略:允许开发者对同一层级的同组子节点,添加唯一 key 进行区分,虽然只是小小的改动,性能上却发生了翻天覆地的变化!
以下图为例:
lastIndex: 当前比较过的节点在旧集合中最大的索引值
nextIndex:当前比较的节点在新集合中的索引值
nextChildren:新节点集合
prevChildren:旧节点集合
name: 唯一的key
nextChild:当前比较的节点在新集合中的节点
prevChild:当前比较的节点在旧集合中的节点
_mountIndex:节点在集合中的索引
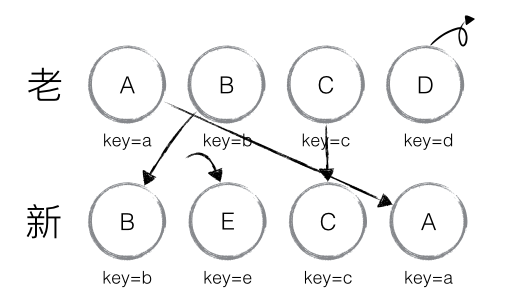
比较的关键点:prevChild._mountIndex < lastIndex - 从新集合中取得 B,判断老集合中存在相同节点 B,由于 B 在老集合中的位置 B._mountIndex = 1,此时 lastIndex = 0,因此不对 B 进行移动操作;更新 lastIndex = 1,并将 B 的位置更新为新集合中的位置 B._mountIndex = 0,nextIndex++进入下一个节点的判断。
- 从新集合中取得 E,判断老集合中不存在相同节点 E,则创建新节点 E;更新 lastIndex = 1,并将 E 的位置更新为新集合中的位置,nextIndex++进入下一个节点的判断。
- 从新集合中取得 C,判断老集合中存在相同节点 C,由于 C 在老集合中的位置C._mountIndex = 2,此时 lastIndex = 1,因此对 C 进行移动操作;更新 lastIndex = 2,并将 C 的位置更新为新集合中的位置,nextIndex++ 进入下一个节点的判断。
- 从新集合中取得 A,判断老集合中存在相同节点 A,由于 A 在老集合中的位置A._mountIndex = 0,此时 lastIndex = 2,因此不对 A 进行移动操作;更新 lastIndex = 2,并将 A 的位置更新为新集合中的位置,nextIndex++ 进入下一个节点的判断。
- 当完成新集合中所有节点 diff 时,最后还需要对老集合进行循环遍历,判断是否存在新集合中没有但老集合中仍存在的节点,发现存在这样的节点 D,因此删除节点 D,到此 diff 全部完成。
当然,React diff 还是存在些许不足与待优化的地方,如下图所示,若新集合的节点更新为:D、A、B、C,与老集合对比只有 D 节点移动,而 A、B、C 仍然保持原有的顺序,理论上 diff 应该只需对 D 执行移动操作,然而由于 D 在老集合的位置是最大的,导致其他节点的 _mountIndex < lastIndex,造成 D 没有执行移动操作,而是 A、B、C 全部移动到 D 节点后面的现象。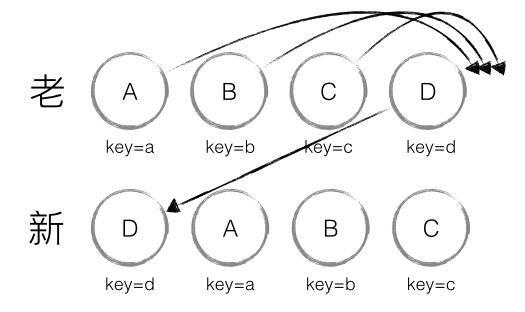
patch
前面一系列的操作都是针对Virtual DOM进行的,浏览器中并未能显示出更新的数据,patch实现了关键的最后一步,将diff算法计算出来的DOM差异队列更新到真实的DOM节点上,最终让浏览器能够渲染出更新的数据。它主要是通过遍历差异队列,根据更新类型进行相应的操作,如新节点的插入,已有节点的移动和移除等。
参考文献:
《深入React技术栈》陈屹
React源码分析5 — setState机制